2026 Guide to Cost-Efficient AI: Mastering Prompt Caching and Sustainable Laravel Architecture

By Abo-Elmakarem Shohoud | Ailigent
As we navigate the technological landscape of 2026, the initial hype surrounding Generative AI has matured into a focused pursuit of efficiency and scalability. For business owners and tech professionals, the goal is no longer just to build an AI agent, but to build one that is cost-effective, maintainable, and robust. This tutorial explores two critical pillars of modern software development: optimizing inference costs on Amazon Bedrock and preventing technical debt in Laravel-based AI applications.
 How to Implement Prompt Caching on Amazon Bedrock and Cut Inference Costs in Half
Source: Dev.to AI
How to Implement Prompt Caching on Amazon Bedrock and Cut Inference Costs in Half
Source: Dev.to AI
Learning Objectives
By the end of this tutorial, you will be able to:
- Implement Prompt Caching on Amazon Bedrock to reduce token costs by up to 50%.
- Identify and refactor technical debt in Laravel projects to ensure long-term agility.
- Architect a support agent that balances high-speed responses with budget constraints.
- Apply clean code principles to AI-integrated web applications.
Section 1: The Economics of AI in 2026
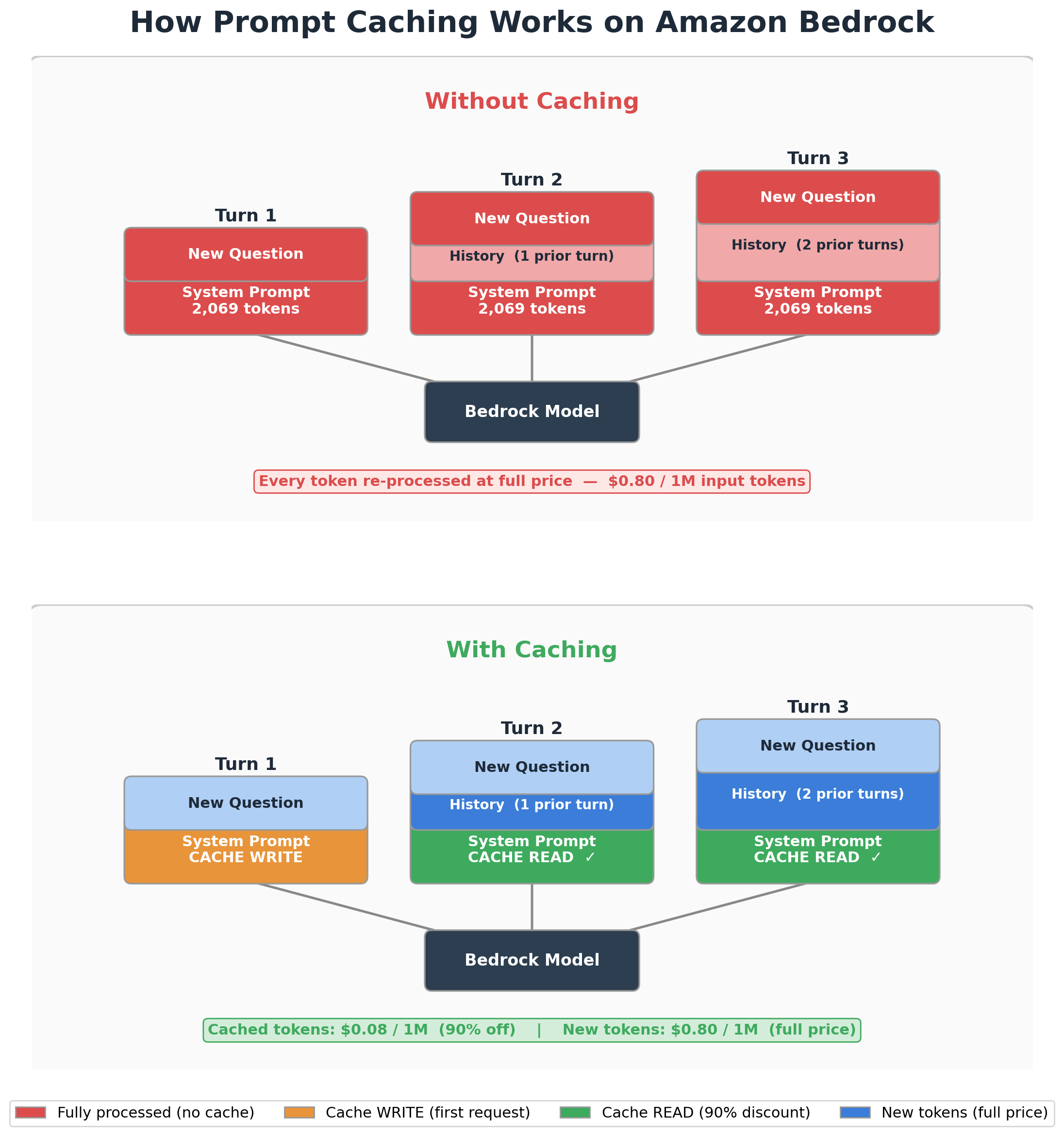
In 2026, the volume of data processed by Large Language Models (LLMs) has reached unprecedented levels. However, many organizations still struggle with the "token tax." Every time your support agent answers a customer, it re-reads your system prompt, product documentation, and conversation history. This repetitive processing is the primary driver of high API bills.
Prompt Caching is a technique that allows the model provider to store frequently used context (like system instructions or documentation) so it doesn't have to be re-processed for every single API call.
At Ailigent, we have observed that for a standard multi-turn conversation using models like Nova Pro, over 80% of the input tokens are static. By caching these tokens, businesses can drastically reduce their overhead. Abo-Elmakarem Shohoud emphasizes that efficiency in 2026 isn't just about faster models, but about smarter utilization of resources.
Section 2: Implementing Prompt Caching on Amazon Bedrock
Amazon Bedrock has introduced sophisticated caching mechanisms that allow developers to flag specific parts of their prompt as "cacheable." This is particularly useful for multi-turn support agents where the "Persona" and "Knowledge Base" remain constant.
Step-by-Step Walkthrough
- Identify the Static Content: Separate your system prompt (persona, rules) from the dynamic user input.
- Use the Converse API: Bedrock's Converse API allows for structured message passing. You must identify the "checkpoint" where the cache should end.
- Set the TTL (Time to Live): Cached content usually persists for a specific duration (e.g., 300 seconds of inactivity).
Code Example (Python/Boto3):
import boto3
client = boto3.client('bedrock-runtime')

*Source: Dev.to AI*
# Defining a cached system prompt
system_content = [
{
"text": "You are a highly skilled support agent for Ailigent. Use the following docs...",
"cachePoint": { "type": "default" } # This flags the content for caching
}
]
response = client.converse(
modelId='amazon.nova-pro-v1:0',
messages=[{"role": "user", "content": [{"text": "How do I reset my password?"}]}],
system=system_content
)
print(f"Input tokens: {response['usage']['inputTokens']}")
print(f"Cached tokens: {response['usage'].get('cacheReadTokens', 0)}")
Try it yourself: Monitor your AWS CloudWatch logs after implementing this. You should see a significant drop in InputTokens and a corresponding rise in CacheReadTokens for repeat sessions.
Section 3: Eliminating Technical Debt in Laravel
While AI provides the intelligence, your application framework—likely Laravel in 2026—provides the structure. Technical debt in Laravel often starts with "Fat Controllers" and ends with a codebase that is impossible to update.
Technical Debt is the implied cost of additional rework caused by choosing an easy (limited) solution now instead of using a better approach that would take longer.
Common Laravel Pitfalls in AI Apps
- Logic in Controllers: Placing API calls to Bedrock directly inside
StoreCommentControllermakes testing impossible. - Duplicate Prompt Templates: Hardcoding prompts in multiple files leads to inconsistent AI behavior.
- Synchronous Processing: Running heavy AI inference during the request-response cycle, leading to timeouts.
The 2026 Solution: Actions and Services
Instead of fat controllers, use Action Classes. An action class encapsulates a single business task, such as GenerateSupportResponse.
| Feature | Traditional Approach (High Debt) | Modern Laravel (Low Debt) |
|---|---|---|
| Logic Location | Controller Methods | Dedicated Action/Service Classes |
| AI Interaction | Inline API Calls | Abstracted Repositories |
| Prompt Management | Hardcoded Strings | Config/View-based Templates |
| Execution | Synchronous | Queued Jobs (Laravel Horizon) |
Section 4: Building the Scalable Support Agent
For small businesses, the goal is to provide 24/7 support without hiring a massive team. By combining Bedrock's Prompt Caching with a clean Laravel backend, you create a system that is both cheap to run and easy to maintain.
Step 1: The Service Layer
Create a BedrockService that handles the authentication and caching logic. This keeps your AI logic centralized.
Step 2: The Queue System Use Laravel Queues to handle AI responses. This ensures that even if Bedrock takes 5 seconds to generate a response, your user's browser doesn't hang.
Step 3: Monitoring and Iteration In 2026, observability is key. Track the cost per conversation. If the cost exceeds $0.05 per session, revisit your caching strategy.
Key Takeaways
- Prompt Caching is essential: In 2026, failing to use caching on platforms like Amazon Bedrock means you are literally throwing away 50% of your AI budget.
- Structure over Speed: Laravel's rapid development cycle is a trap if not managed with Service Classes and Actions. Avoid technical debt early to maintain agility.
- Small Business Advantage: AI allows small teams to compete with enterprises, but only if the underlying architecture is sustainable and cost-effective.
- Ailigent's Philosophy: Always decouple your AI logic from your web logic to ensure that as models evolve, your application doesn't break.
Next Steps
- Audit your current Bedrock usage: Check your AWS Billing dashboard for "Input Tokens" and calculate potential savings from caching.
- Refactor one controller: Take your most complex Laravel controller and move the business logic into a dedicated Service class.
- Explore Agentic AI: Once your costs are optimized, look into multi-agent systems that can handle complex tasks autonomously.