Scaling AI Legal Intelligence: A 2026 Guide to Agentic MLOps and High-Fidelity Data Extraction

By Abo-Elmakarem Shohoud | Ailigent
Introduction: The Era of Specialized Agentic AI
 I'm Hwiyul, Leader 01 of Lawmadi OS — Your AI Civil Law Expert for Contracts, Debts, and Lawsuits
Source: Dev.to AI
I'm Hwiyul, Leader 01 of Lawmadi OS — Your AI Civil Law Expert for Contracts, Debts, and Lawsuits
Source: Dev.to AI
As of March 13, 2026, the landscape of artificial intelligence has shifted from general-purpose chatbots to highly specialized, autonomous agents. We are no longer asking if AI can write a legal summary; we are deploying systems that can manage contract disputes, track debts, and prepare lawsuit filings with minimal human intervention. This tutorial focuses on the technical architecture required to build and scale these systems, specifically focusing on the intersection of high-fidelity data extraction and containerized MLOps pipelines.
In the current 2026 market, the demand for precision in legal AI is non-negotiable. Specialized agents like Hwiyul, the leader of the Lawmadi OS lineup, represent the gold standard. Hwiyul specializes in Civil Law (민사법), focusing on contract disputes and debt recovery. However, to build an agent of this caliber, you need more than just a large language model (LLM). You need a robust data pipeline that can ingest complex legal PDFs and a deployment strategy that ensures reliability across different environments.
Learning Objectives
- Understand the role of hybrid engines in PDF data extraction (using Hancom OpenDataLoader v2.0 as a benchmark).
- Learn the architectural patterns of specialized legal agents.
- Master the process of containerizing an MLOps pipeline from training to serving.
- Implement a scalable workflow for civil law automation.
Phase 1: High-Fidelity Data Extraction with Hancom OpenDataLoader PDF v2.0
Legal documents are notoriously difficult to parse. They contain nested tables, complex formatting, and specific terminology that traditional OCR often fails to capture accurately. In 2026, the industry has moved toward hybrid extraction engines.
Hancom OpenDataLoader PDF v2.0 is a hybrid engine that combines AI-based vision models with direct programmatic extraction methods to achieve top-tier data accuracy from unstructured PDF files.
When building a legal agent, your first step is ensuring the ground truth data is perfect. Hancom’s v2.0 has set the benchmark for open-source performance by using a dual-pathway approach. It doesn't just 'look' at the text; it analyzes the underlying metadata of the PDF while simultaneously using AI to interpret the visual layout. This is crucial for civil law contracts where a single misread clause in a debt agreement can lead to significant financial liability.
Why Hybrid Extraction Matters in 2026
- Transparency: Open-source benchmarks allow developers to verify the extraction logic.
- Accuracy: AI-based vision handles scanned documents, while direct extraction handles digital-first PDFs.
- Speed: Optimized codebases allow for real-time processing of thousands of legal pages.
Phase 2: Building the Specialized Agent (The Lawmadi OS Model)
Once the data is extracted, it must be processed by a specialized agent. Agentic AI is a paradigm where AI systems are designed to perceive their environment, reason about goals, and take autonomous actions to achieve specific outcomes.
Take the example of Hwiyul, the Lawmadi OS leader. Hwiyul isn't a generalist; it is specifically tuned for Civil Law. This specialization is what Abo-Elmakarem Shohoud emphasizes at Ailigent: the future of AI is not one model that does everything, but a coordinated "OS" of 60+ agents, each mastering a niche.
Core Specialized Domains for Civil Law Agents:
- Contract Disputes: Analyzing breaches of contract and identifying legal remedies.
- Debt Recovery: Automating the tracking of owed amounts and generating legal notices.
- Procedural Lawsuits: Ensuring all filings meet the strict formatting and timing requirements of the court system.
| Feature | General LLM | Specialized Legal Agent (e.g., Lawmadi) |
|---|---|---|
| Contextual Depth | Broad but shallow | Deep understanding of regional civil codes |
| Accuracy | Prone to hallucinations in legal citations | RAG-enhanced (Retrieval Augmented Generation) |
| Actionability | Provides advice | Executes document preparation and filing |
| Data Handling | Basic text input | High-fidelity PDF ingestion (Hancom v2.0) |
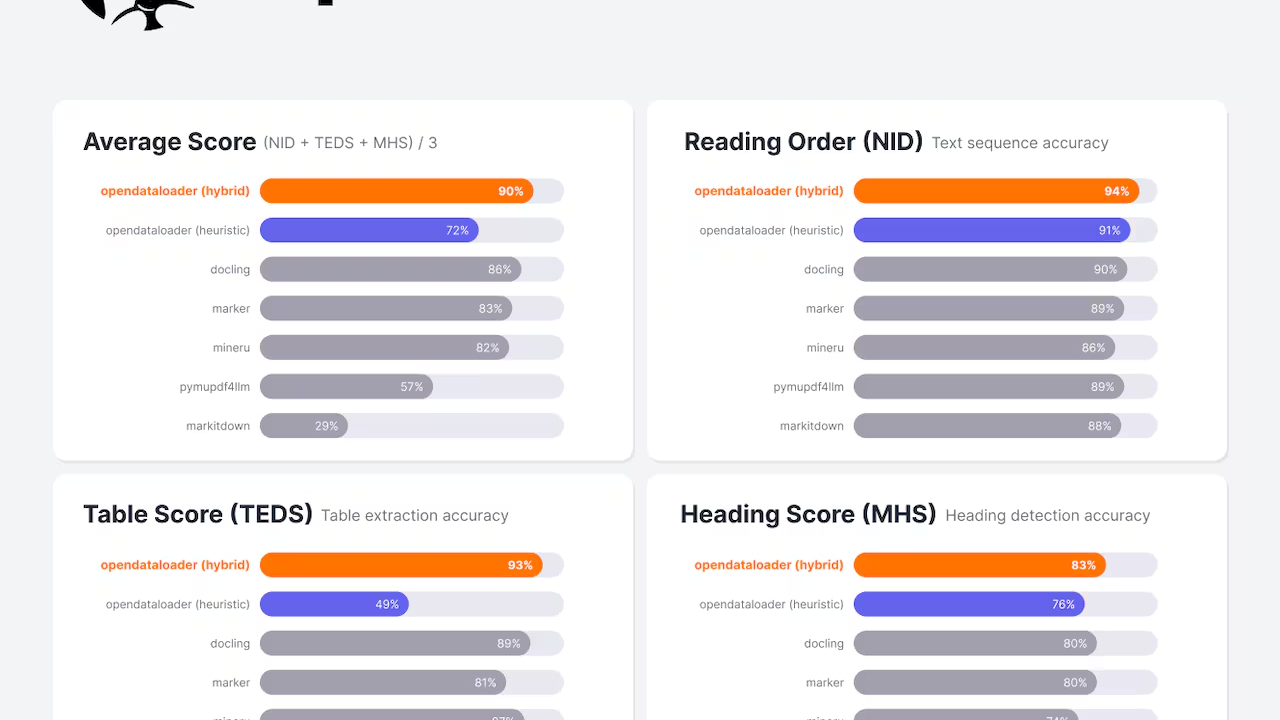 Hancom Unveils 'OpenDataLoader PDF v2.0' "Ranked No. 1 in Open Source PDF Data Extraction Benchmarks"
Source: Dev.to AI
Hancom Unveils 'OpenDataLoader PDF v2.0' "Ranked No. 1 in Open Source PDF Data Extraction Benchmarks"
Source: Dev.to AI
Phase 3: Containerizing Your MLOps Pipeline
Building the model is only 20% of the battle. The remaining 80% is operationalizing it. This is where MLOps comes in.
MLOps is a set of practices that aims to deploy and maintain machine learning models in production reliably and efficiently.
In 2026, we use containerization (Docker and Kubernetes) to ensure that the model that worked in your local Jupyter notebook also works in the enterprise cloud. A fragmented pipeline—where training happens in one environment and serving in another—is a recipe for disaster in legal tech.
Step-by-Step Walkthrough: Containerization
1. Define the Environment
Create a Dockerfile that includes all dependencies for Hancom extraction and the agentic logic.
# Use a specialized 2026 AI base image
FROM ai-runtime-2026:latest
# Install Hancom OpenDataLoader v2.0 dependencies
RUN pip install hancom-dataloader-v2
# Copy specialized legal weights (e.g., Lawmadi civil law fine-tunes)
COPY ./models/hwiyul_v1 /app/models/
# Set up the serving API
COPY ./api /app/api
WORKDIR /app
CMD ["python", "api/server.py"]
2. Orchestrate the Pipeline
Use a CI/CD tool to automate the transition from training (where the agent learns from new civil law precedents) to serving (where the agent interacts with clients).
3. Implement Monitoring
In 2026, we monitor not just for uptime, but for "Legal Drift." If the civil law code is updated by the government, the agent's performance will degrade. Your MLOps pipeline must trigger a re-training cycle automatically.
Exercise: Try it Yourself
Objective: Extract a clause from a sample debt agreement and determine if it constitutes a breach under 2026 civil standards.
- Download a sample debt PDF from the Hancom GitHub repository.
- Run the extraction script to convert the PDF into structured JSON.
- Prompt a mock agent with the JSON data: "Based on the extracted 'Repayment Schedule' and 'Default' clauses, has the debtor breached the contract if the payment was 3 days late?"
- Observe how the structured data from Hancom improves the agent's reasoning compared to pasting raw text.
Key Takeaways
- Hybrid Data is King: High-fidelity extraction using tools like Hancom v2.0 is the foundation of reliable AI. Without clean data, even the best legal agent will fail.
- Specialization Wins: In 2026, enterprise value lies in specialized agents (like Hwiyul for Civil Law) rather than general-purpose models.
- Containerize Everything: To scale AI in a business environment, your MLOps pipeline must be containerized to ensure consistency from training to production.
- Continuous Evolution: Legal AI requires constant monitoring for regulatory updates and data drift to remain compliant and effective.
Next Steps
To further your expertise, explore the Lawmadi OS documentation to see how 60 specialized agents interact in a multi-agent system. Additionally, dive into the Hancom GitHub repository to experiment with the reproducible code for PDF v2.0. Stay tuned to the Ailigent blog for more insights from Abo-Elmakarem Shohoud on the future of automation.