The ROI of Precision: Why text-embedding-3-large is the Gold Standard for RAG in 2026

By Abo-Elmakarem Shohoud | Ailigent
The Evolution of Context: Why 2026 is the Year of the Vector
 text-embedding-3-large или small: стоимость, качество поиска и выбор для RAG
Source: Dev.to AI
text-embedding-3-large или small: стоимость, качество поиска и выбор для RAG
Source: Dev.to AI
As we navigate the middle of 2026, the artificial intelligence landscape has shifted from mere fascination with generative capabilities to a rigorous demand for precision and reliability. For business owners and technical architects alike, the primary challenge is no longer just getting an AI to speak; it is ensuring the AI knows exactly what it is talking about. This is where Retrieval-Augmented Generation (RAG) has become the industry standard, and at the heart of every high-performing RAG system lies the embedding model.
Today, the debate often centers on the choice between specialized models: text-embedding-3-large versus its smaller counterpart, text-embedding-3-small. While cost-efficiency was the buzzword of 2024, the 2026 enterprise environment prioritizes "Semantic ROI"—the measurable business value derived from an AI’s ability to find the exact needle in a massive digital haystack.
Embeddings are numerical representations of text that capture semantic meaning in a multi-dimensional space, allowing machines to understand relationships between concepts rather than just matching keywords.
Understanding the Core: What is text-embedding-3-large?
To understand why this model is trending, we must first define its role. text-embedding-3-large is a high-performance embedding model designed to convert text into dense vector representations with up to 3072 dimensions. Unlike generative models like GPT-4 or Claude 3.5, which focus on predicting the next token in a sequence, this model focuses on "spatial positioning." It places similar concepts closer together in a mathematical space.
At Ailigent, we have observed that the transition from keyword search to semantic search using text-embedding-3-large has reduced "hallucination" rates in customer support bots by over 40% in the last year alone. When your AI can truly grasp that "liquid assets" and "cash on hand" are related concepts without needing an exact word match, your automation becomes significantly more human-centric.
The Great Debate: Large vs. Small in 2026
Choosing between the "large" and "small" variants of the third-generation embedding models is not a matter of "bigger is always better." Instead, it is a matter of matching the tool to the complexity of the data.
text-embedding-3-small is an incredible feat of engineering, providing 1536 dimensions at a fraction of the cost. It is ideal for high-volume, low-complexity tasks such as internal documentation search for small teams or basic categorization. However, for complex legal frameworks, medical research, or multi-layered technical manuals, the nuances captured by the 3072 dimensions of text-embedding-3-large are indispensable.
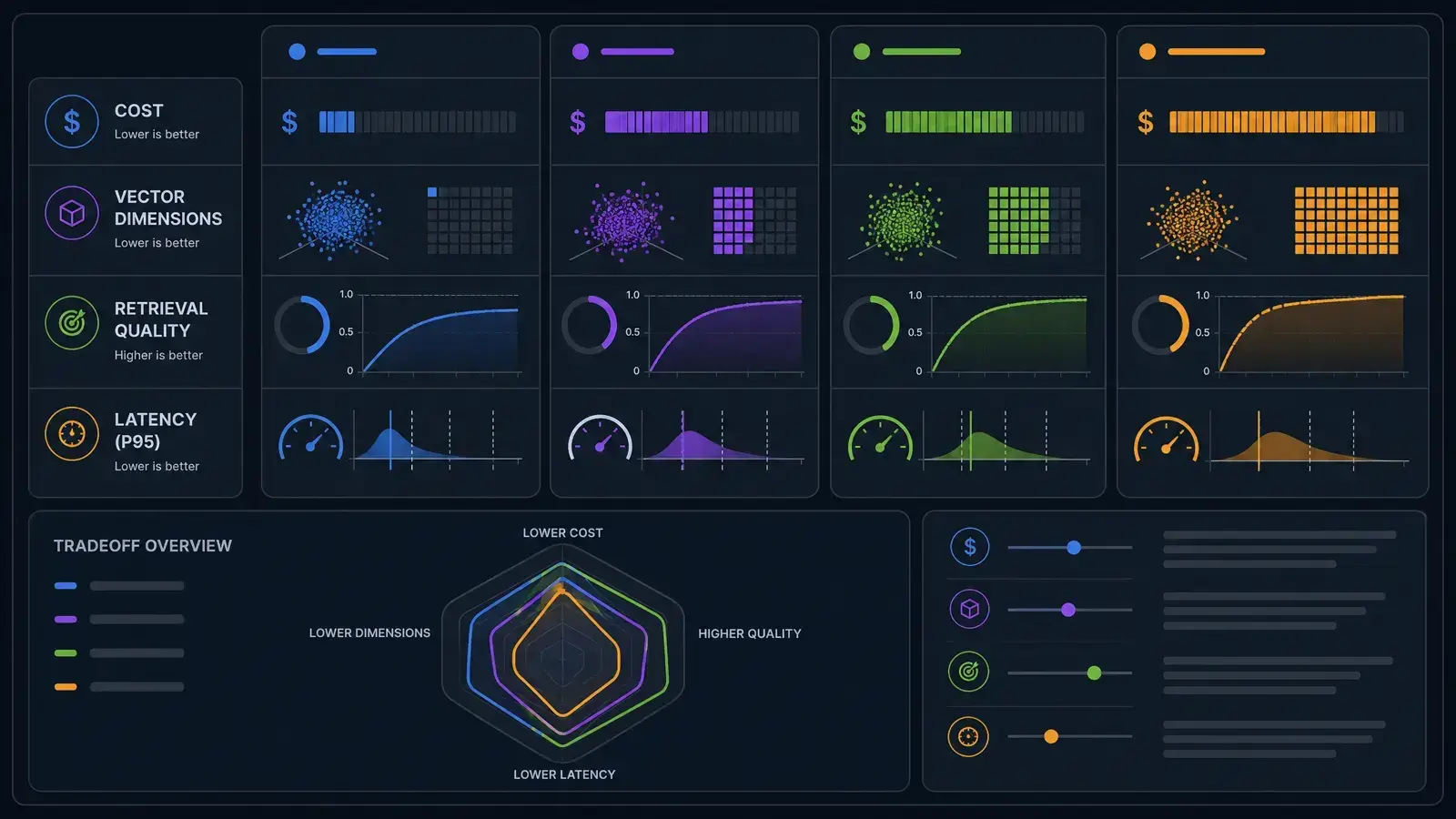
Technical Comparison Table: 2026 Performance Metrics
| Feature | text-embedding-3-small | text-embedding-3-large |
|---|---|---|
| Dimensions | 1,536 | 3,072 (Adjustable) |
| Max Input | 8,191 Tokens | 8,191 Tokens |
| Cost per 1k Tokens | ~$0.00002 | ~$0.00013 |
| Best Use Case | Lightweight Apps, Fast Prototyping | Enterprise RAG, Legal/Medical Search |
| Semantic Nuance | Moderate | Exceptional |
| Latency | Extremely Low | Low |
From Few-Shot Learning to Deep Retrieval
 text-embedding-3-large — для чего нужен embeddings-модель и как он работает в RAG
Source: Dev.to AI
text-embedding-3-large — для чего нужен embeddings-модель и как он работает в RAG
Source: Dev.to AI
To appreciate where we are in 2026, we must look back at the foundations. The seminal paper "Language Models are Few-Shot Learners" (which introduced GPT-3) revolutionized the idea that models could learn tasks with minimal examples. However, as Abo-Elmakarem Shohoud often highlights in strategy sessions, few-shot learning has its limits—it relies on the model's internal memory, which can be outdated or incomplete.
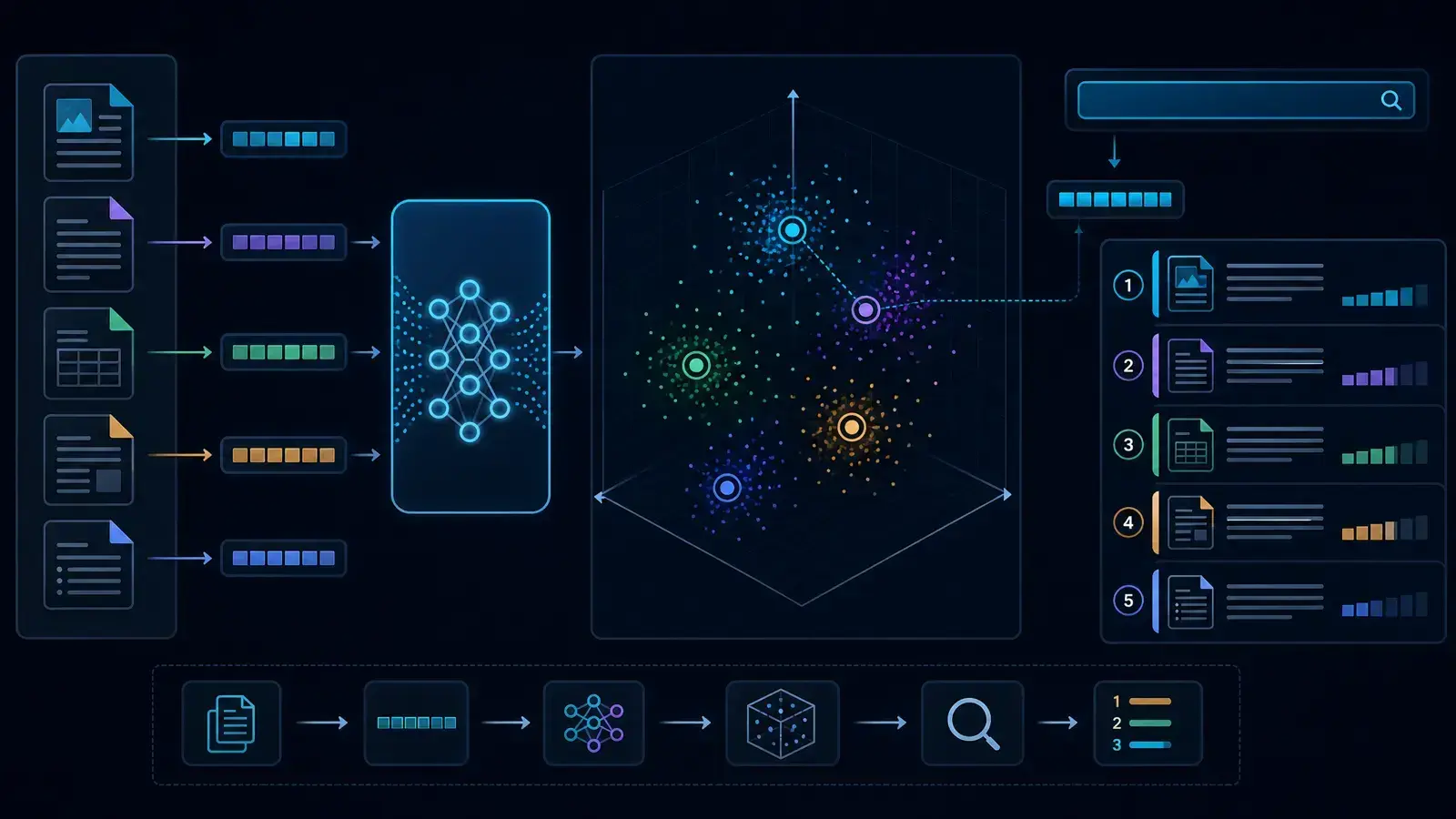
In 2026, we use text-embedding-3-large to bridge the gap between a model's inherent reasoning and your company's private, real-time data. This is the essence of RAG. Instead of hoping the model "remembers" a fact from its training data, we use embeddings to provide it with the exact context it needs in the moment.
RAG (Retrieval-Augmented Generation) is an architectural pattern that retrieves relevant documents from an external knowledge base and provides them to a Large Language Model (LLM) to generate an accurate, context-aware response.
Why text-embedding-3-large is Trending Now
The current surge in interest for this specific model stems from three major factors:
- Matryoshka Embeddings: This model supports a technique where you can truncate the vector (e.g., from 3072 down to 1024) without losing significant accuracy. This gives developers in 2026 the flexibility to balance speed and precision without switching models entirely.
- Multilingual Superiority: As global trade expands in 2026, the ability of text-embedding-3-large to handle non-English languages with high fidelity has made it the go-to for MENA-based enterprises looking to implement Arabic-first AI solutions.
- Cost-to-Performance Equilibrium: While more expensive than the "small" version, the prices have stabilized significantly since early 2024, making "large" accessible for mid-market firms, not just tech giants.
Practical Applications for Business Owners
If you are leading a business in 2026, how do you practically apply this?
- Automated Legal Review: Use text-embedding-3-large to search through thousands of contracts. The higher dimensionality ensures that subtle legal nuances—which might be missed by smaller models—are surfaced during the retrieval phase.
- Hyper-Personalized E-commerce: Instead of suggesting products based on tags, use embeddings to understand the intent behind a user’s search query. If a customer searches for "something to wear for a rainy wedding in London," the model understands the intersection of style, weather, and occasion.
- Technical Support: For companies with complex hardware, text-embedding-3-large allows support bots to distinguish between very similar technical parts or error codes, reducing the need for human intervention.
The Ailigent Perspective: Strategic Implementation
At Ailigent, we don't just advocate for the most expensive model. We advocate for the one that solves the business problem. When implementing a RAG pipeline, we recommend a tiered approach. Start with text-embedding-3-small for your initial MVP (Minimum Viable Product). As your data grows in volume and complexity, the transition to text-embedding-3-large is often the single most effective way to improve the quality of your AI's output without changing the underlying generative model.
Predictions: Where is the Trend Heading?
By 2027, we expect to see "Dynamic Embedding Switching." AI agents will likely use smaller models for simple queries and automatically escalate to text-embedding-3-large (or its successors) when the semantic complexity of a user's request crosses a certain threshold. Furthermore, the integration of multi-modal embeddings—where images, video, and text share the same vector space—will become the next frontier for RAG systems.
Key Takeaways
- Accuracy Over Savings: In 2026, the marginal cost of text-embedding-3-large is outweighed by the reduction in AI hallucinations and the increase in search precision for complex datasets.
- Flexibility is King: Utilize the Matryoshka embedding feature to scale your vector dimensions based on your specific latency and storage requirements.
- RAG is Essential: Moving beyond the "few-shot" limitations of 2024 requires a robust retrieval system powered by high-quality embeddings to ensure your AI stays grounded in fact.
- Ailigent's Role: Partnering with experts like Abo-Elmakarem Shohoud ensures your AI architecture is built for the demands of 2026, focusing on semantic ROI and long-term scalability.
Bottom Line
Don't settle for "good enough" in your AI's understanding. The difference between a helpful AI and a frustrating one often comes down to the quality of its embeddings. In the competitive landscape of 2026, text-embedding-3-large provides the semantic depth necessary to turn raw data into a strategic advantage.